Overview
A web app that registers users with a short voice sample and later verifies their identity from a new recording. No SaaS API in the loop — embeddings are extracted locally with PyAnnote-Audio, stored as vectors in ChromaDB, and matched by cosine similarity. The UI surfaces the raw similarity score and a projection of the embedding so the verification result is auditable, not just a yes/no.
Why I built it
I wanted to understand voice biometrics end-to-end rather than treat it as a black box. The interesting part isn't the UI — it's the path from a 44.1 kHz audio file to a fixed-length vector that's stable enough to match the same speaker across recordings, weeks apart, on different microphones. Doing every layer myself was the point: the model, the vector store, the distance metric, the API, the visualization. The project is small on purpose — one job, all of it visible.
How verification works
Browser records 16-bit PCM via MediaRecorder, posts the blob as multipart form-data. The backend resamples to 16 kHz mono — the rate PyAnnote's embedding model expects.
PyAnnote-Audio's pretrained speaker-embedding model produces a fixed-length vector summarising the voice — pitch, formants, timbre, speaking rate — independent of what was said.
On enrolment, the embedding lands in ChromaDB keyed by user ID. On verification, the new embedding is compared against the stored one with cosine similarity; ChromaDB does the math and returns a score.
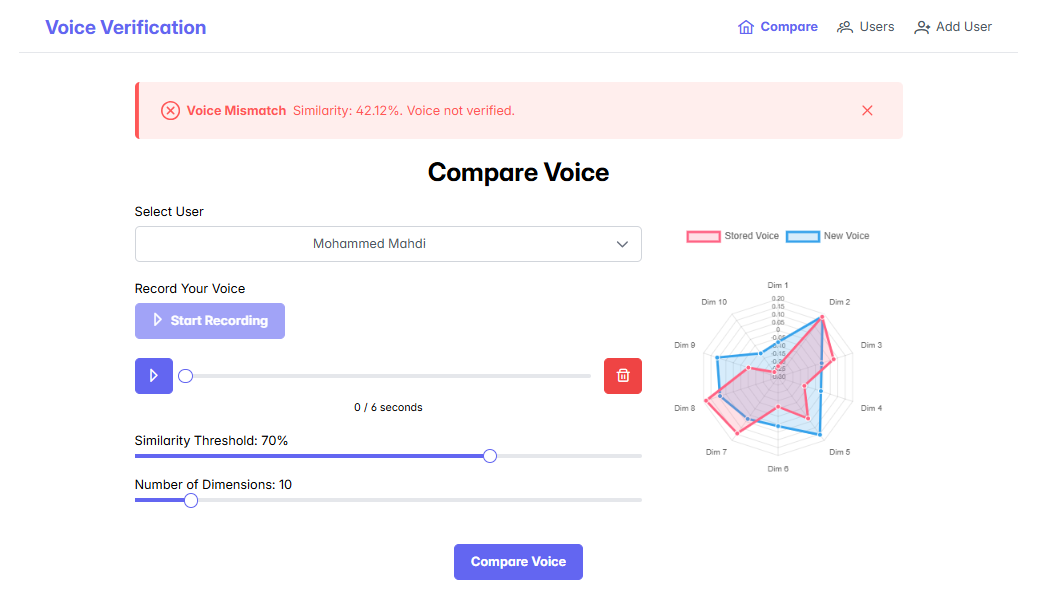
A threshold on the similarity score becomes the accept/reject decision. The score is shown in the UI alongside a radar projection of the two embeddings so a human can sanity-check the result.
Stack and shape
The split is deliberate. ChromaDB owns the vectors (it's built for nearest- neighbour search and embeds-out-of-the-box ergonomics matter more than raw throughput at this scale). SQLite owns the structured user data — name, email, foreign-key to the embedding. The two stores stay in their lane; neither tries to be the other.
The frontend is React + PrimeReact on Vite. PrimeReact was an experiment — I'd worked with shadcn/ui and Tailwind by default; this project was the "try the other end of the component-library spectrum" run. The result was useful: PrimeReact ships a lot, and quickly, but the styling escape hatches are awkward enough that I went back to shadcn for everything since.
Things worth pointing at
Embedding visualization. A radar chart projects N dimensions of the two embeddings — the live sample and the stored one — onto a single shape. It doesn't replace the similarity score, but it makes the score legible: two voices that match overlap; two that don't fan out. Useful when explaining to someone who's never seen a vector before.
Shimmer loading on every async surface. The list pages don't pop empty-then-full; they render skeleton rows and morph in. It's three extra components and ten lines of CSS for a noticeable perceived-latency win.
Cascading deletes across two stores. When a user is deleted, the row in SQLite goes away and so does the corresponding vector in ChromaDB. The two writes happen in sequence inside one request handler; if the second fails, the API returns a partial-state error rather than silently orphaning a vector. It's not a transaction across two stores — there isn't one available — but the failure mode is at least visible.
What I'd change
This is what I'd do differently if I picked the project up again, not a feature wishlist.
- Real auth. It's a single-tenant demo. A real version would put every endpoint behind JWT and scope users + embeddings per tenant.
- Threshold per user, not global. Cosine similarity baselines differ across voices; a fixed cutoff under-rejects some speakers and over-accepts others. A short calibration phase per enrolment would fix that.
- Liveness check. The current flow can't tell a live speaker from a recording held to the microphone. A challenge-response (read this random phrase) closes that hole at the cost of a slower enrolment.
- Better feedback on duplicate emails. The known issue from the README — registration fails with a generic "Failed to register user" when the email is already taken. Should be a 409 with a precise message; the front-end can route the user to the existing profile.
Repo
Source on GitHub. MIT.